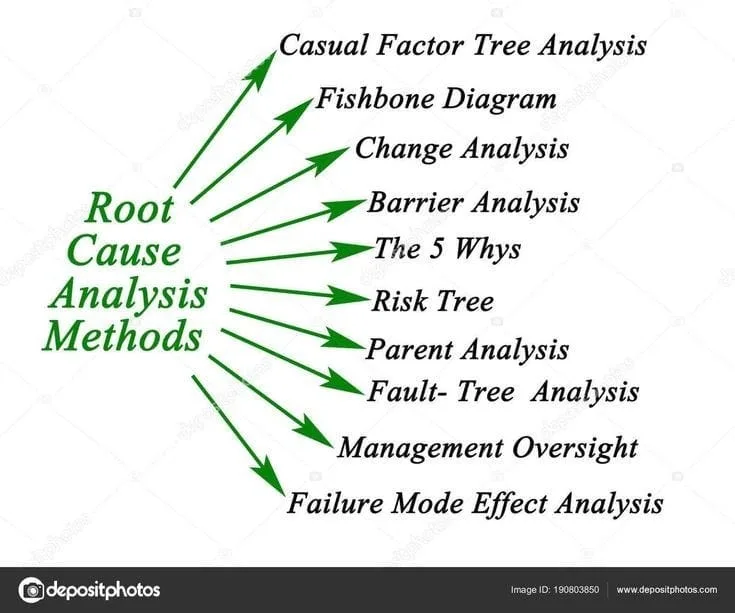
Une analyse de cause racine (En anglais — Root Cause Analysis, RCA) est une démarche structurée pour identifier, de façon exhaustive et précise, les causes fondamentales d’un incident ou d’une non‑conformité.
Je suis tombé sur cette image voilà quelques mois lors d’une recherche internet pour un client et je la toujours conservé parce-que je la trouve simple, j’en profite pour aborder le sujet avec vous.
Mes clients me demande toujours plus d’information sur comment faire ce type d’analyse, alors j’utilise cet article comme références.
Dans un Système de Gestion de la sécurité de l’information (SGSI) l’analyse de cause racine cherche à comprendre pourquoi un événement s’est produit et comment empêcher qu’il se reproduise..
C’est une partie importante et fondamentale du cycle d’amélioration continue PDCA (Plan‑Do‑Check‑Act)
L’analyse de cause racine est dans la phase Check, qui permets les décisions de la phase Act et confirme la pertinence des actions correctives exigées par la clause Non‑conformité et action corrective (ISO 27001 clause10.1).
Concrètement, sans une bonne compréhension des causes, l’organisation risque de ne corriger que des symptômes, laissant les problèmes se répéter.
Lien avec la norme ISO/IEC 27001:2022
Plusieurs références ont lieux à l’analyse des causes racines dans la norme ISO27001:2022.
- Clause 6.1.2 — Analyse et appréciation des risques pour bien comprendre les scénarios de menaces
- Clause 9.1 — demande la collecte de données fiables et l’analyse des causes racines transforme ces données en renseignements utilisable pour l’avenir.
- Clause 10.2 — La clause principale de gestion des non conformité et création d’action corrective demande que chaque NC soit évalué pour connaitre les cause et donc d’empêcher une répétition.
The 5 Whys (Les cinq pourquoi)
La méthode des 5 Pourquoi consiste à poser la question « Pourquoi ? » de façon répétée pour remonter des symptômes d’un problème jusqu’à sa cause fondamentale.
En trouvant cette cause racine, on peut appliquer une action corrective qui élimine durablement le problème plutôt que d’en masquer les effets.
Sa rapidité et sa simplicité en font un outil privilégié dans les environnements certifiés ISO, parce-qu’elle est simple et efficace.
Elle a des limites face à des incidents complexes lorsque plusieurs causes indépendantes interagissent.
Comment faire une analyse des 5 pourquoi
1 — Formule clairement le problème et écris‑le. 2 — Demande : « Pourquoi ce problème survient‑il ? » et note la réponse.3 — Transforme cette réponse en un nouveau problème, puis demande encore : « Pourquoi cela arrive‑t‑il ? » et écris la nouvelle réponse.4 — Répète la question « Pourquoi ? » jusqu’à ce qu’aucune explication plus profonde ne soit possible ; c’est alors que la cause racine est découverte. 5 — Si plusieurs causes apparaissent en cours de route, conserve‑les : un même problème peut avoir plusieurs causes premières.
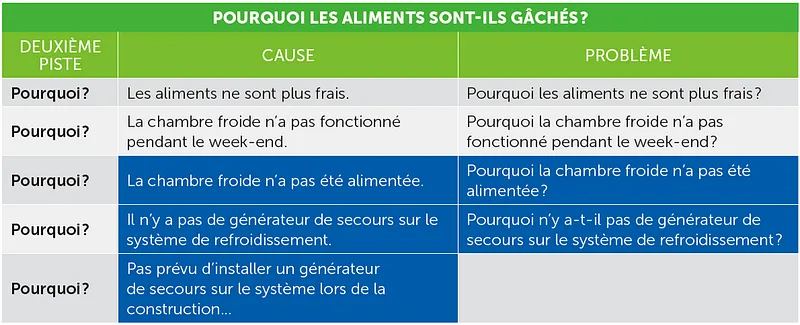
Source — https://www.qualite.qc.ca/ressources/cinq-pourquoi/
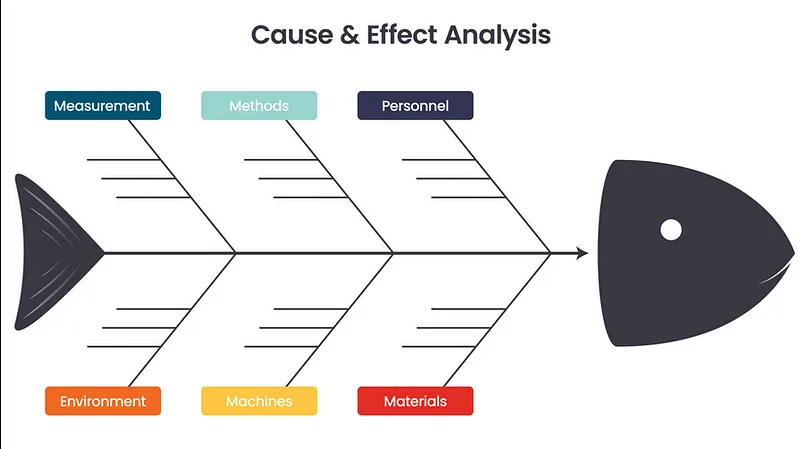
Fishbone Diagram (diagramme d’Ishikawa)
Le diagramme d’Ishikawa représente visuellement l’effet (« arête centrale ») et ses causes potentielles regroupées par catégories (Matériel, Méthodes, Main‑d’œuvre, Milieu, Mesures, etc.).
Il est recommandé lorsqu’un incident résulte d’interactions multiples — typiquement une défaillance de processus ou une erreur humaine couplée à un contrôle technique défaillant.
Sa force réside dans la stimulation de la réflexion collective, utile lors d’ateliers impliquant plusieurs parties prenantes. Sa limite est qu’il cartographie des hypothèses ; une étape de validation est nécessaire pour confirmer la cause première.
On l’utilise surtout quand un problème a plusieurs causes potentielles et qu’on veut structurer la réflexion collective.
Comment crée le diagramme d’Ishikawa
- Définir le problème ou l’effet à analyser. Par exemple : comprendre pourquoi une série de pompes livrées à un client présente fréquemment des défauts.
- Tracer l’ossature du diagramme. Dessinez au centre de la page une flèche horizontale orientée vers la droite ; elle représente l’arête dorsale du poisson. À l’extrémité de la flèche, comme la tête du poisson, inscrivez l’énoncé du problème (p. ex. : défauts fréquents des pompes) et encadrez‐le.
- Identifier les grandes catégories de causes. À partir de l’arête centrale, dessinez des branches obliques qui feront office de côtes. Ishikawa proposait les « 6 M », mais il encourageait l’adaptation des intitulés pour mieux parler aux équipes :
Matériel : pièces, ingrédients, fournitures.
Machinerie : équipements de production, dispositifs de manutention, logiciels (dans certains secteurs, cette catégorie peut être scindée).
Méthodes : procédures, techniques, processus, règlements (notamment pour l’administration publique ou les industries très réglementées).
Mesures : indicateurs clés, instruments de mesure, points de collecte des données.
Main‑d’œuvre : personnes, ressources humaines, formations, compétences.
Milieu (Mother Nature) : environnement et facteurs externes.
On ajoute parfois un septième « M » : Money, c’est‑à‑dire les charges d’exploitation et les investissements.
4.Explorer les causes possibles. En vous appuyant sur ces catégories, demandez : « Pourquoi cela se produit‑il ? » et notez chaque cause plausible sous la branche adéquate, en restant concis. Une même cause peut figurer à plusieurs endroits si elle concerne plusieurs catégories.
5. Approfondir par itérations. Reprenez chaque cause et reposez la question « Pourquoi ? » afin d’atteindre des niveaux plus profonds ; tracez les sous‑causes comme des branches secondaires. L’empilement des branches reflète les relations de causalité.
6. Compléter le brainstorming. Lorsque les idées se tarissent, concentrez‑vous sur les branches où les causes sont moins nombreuses ; cela peut révéler des facteurs négligés.
7. Analyser et hiérarchiser. Examinez l’ensemble des causes recensées pour déterminer lesquelles méritent une action. Gardez à l’esprit que l’objectif est de traiter la cause racine, non les symptômes. Il peut être utile de redessiner le diagramme pour clarifier la présentation avant l’analyse finale.
Fault Tree Analysis (Analyse par l’arbre de défaillances)
L’FTA construit un arbre logique où l’événement indésirable est la racine et les causes sont déployées à l’aide de portes logiques AND/OR.
Cette démarche analytique convient aux événements techniques critiques, tels qu’une indisponibilité majeure d’un service de sécurité.
Elle exige cependant des compétences statistiques et peut devenir lourde pour les petites structures.
Comment crée le FTA (Analyse par arbre de défaillances)
- Identifiez clairement le problème principal à analyser et définissez ses limites.
- Recueillez toutes les informations pertinentes sur le système et consultez les experts concernés.
- Construisez l’arbre en reliant les causes de base au problème principal à l’aide de portes logiques.
- Analysez les chemins dans l’arbre pour comprendre les relations entre les causes et le problème.
- Repérez les événements et les chemins critiques qui influencent le plus la probabilité du problème.
- Développez des stratégies pour atténuer les risques en agissant sur les causes critiques.
- Documentez l’analyse complète et partagez‑la avec les parties prenantes.
- Surveillez l’efficacité des mesures mises en place et mettez régulièrement à jour l’arbre.
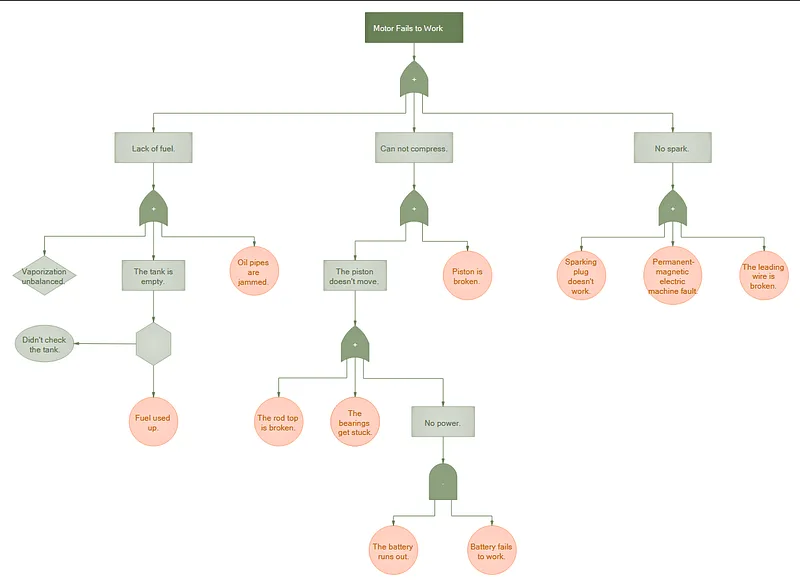
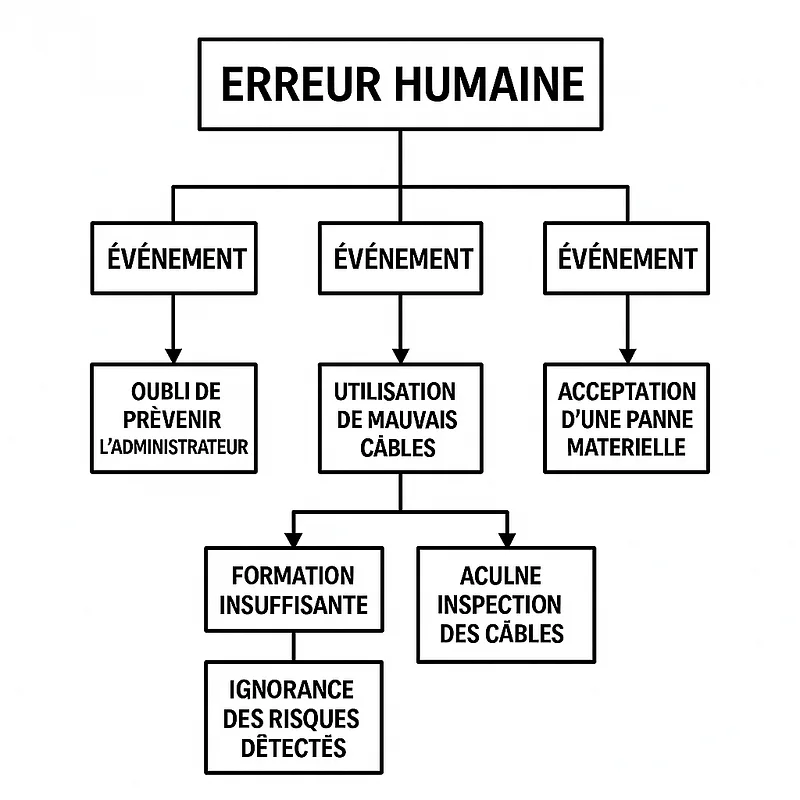
Exempe de FTA
Causal Factor Tree Analysis (Analyse en arbre des facteurs causals)
La CFTA détaille chaque événement contributeur et ses facteurs de causalité dans un arbre chronologique.
L’approche peut être très longue et nécessite des informations précises sur la chronologie des faits.
Comment crée une analyse en arbre des facteurs causals.
- Définir le problème: Écris clairement ce qui s’est passé (l’incident ou le problème principal).
- Chercher des informations: Rassemble les informations sur ce qui s’est passé, comment fonctionne le système et valide avec les personnes concernées.
- Dessiner l’arbre: Note les événements qui ont mené au problème et relie-les comme un arbre, avec des flèches pour montrer le lien.
- Analyser les liens: Regarde comment les événements sont connectés et comprends leur enchaînement.
- Repérer les points importants: Trouve les causes qui ont eu le plus d’impact.
- Chercher des solutions: Note les idées pour éviter que ça recommence.
- Suivre et améliorer: Vérifie plus tard si les solutions fonctionnent et mets à jour l’arbre si besoin.
ChatGPT
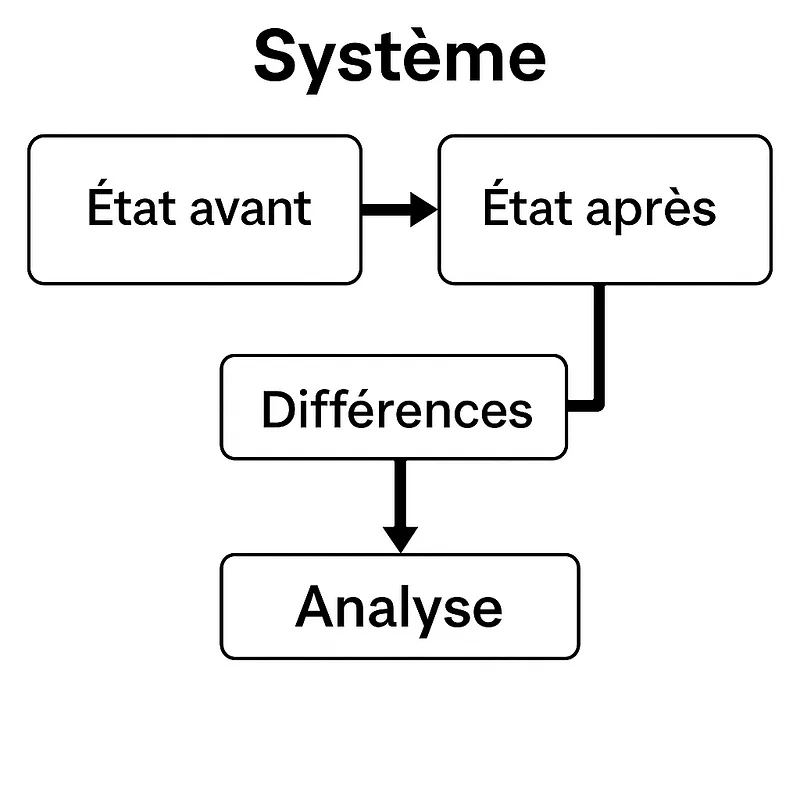
Change Analysis (Analyse des changements)
Cette méthode compare l’état normal d’un système à l’état au moment de l’incident afin de mettre en évidence les modifications ayant pu introduire la non‑conformité.
Elle est particulièrement pertinente pour les environnements agiles ou fortement virtualisés où les mises à jour sont fréquentes.
Sa force est de cibler rapidement un changement mal maîtrisé, aligné avec l’esprit de la clause Gestion des changements (ISO 27002–5.33), même si elle dépend d’un registre de configuration fiable.
Comment faire une anayse des changements
- Définir le système: Identifie clairement ce qui est analysé (processus, équipement, configuration, etc.).
- **Décrire l’état avant: **Note comment le système fonctionnait avant le changement.
- **Décrire l’état après: **Note ce qui a été modifié ou ajouté.
- Comparer les deux états: Repère les différences entre avant et après.
- **Identifier les impacts: **Cherche ce que ces différences ont causé (problèmes, erreurs, améliorations).
- Évaluer: Demande pourquoi ces impacts sont apparus et comment les gérer.
- Documenter l’analyse: Écris un résumé des observations et conclusions.
- Proposer des actions: Suggère des ajustements ou des corrections si nécessaire.
ChatGPT
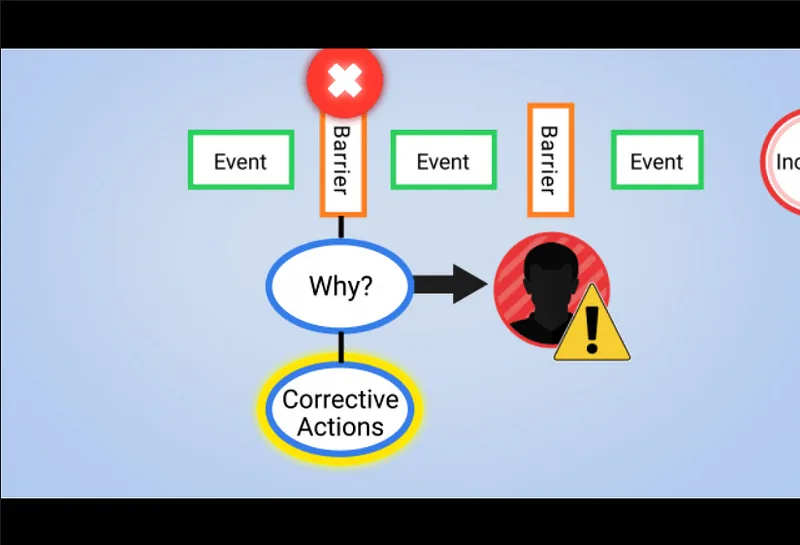
Barrier Analysis (Analyse des barrières)
L’analyse des barrières examine les contrôles existants — physiques, techniques, organisationnels — et détermine lesquels ont échoué ou manqué.
Elle s’appuie aussi sur le modèle du fromage suisse, en évaluant pourquoi plusieurs couches de protection n’ont pas suffi et pourquoi une barrière censée stopper l’incident, comme un mur de béton protégeant des cyclistes, n’a pas fonctionné comme prévu.
La méthode est recommandée lorsque l’incident met en lumière une défense en profondeur insuffisante.
Elle peut également être utilisée pour comprendre ce qui empêche les individus de changer ou d’adopter un nouveau comportement.
Comment faire une analyse des barrières
- Identifier l’incident ou le risque : définissez clairement ce que vous voulez protéger, éviter ou changer.
- Lister les barrières existantes : notez tous les contrôles ou protections en place (techniques, humaines, organisationnelles).
- Vérifier l’efficacité des barrières : évaluez si elles fonctionnent bien et s’il y a des failles.
- Identifier les défaillances ou manques : cherchez ce qui a échoué ou ce qui manque comme barrière.
- Proposer des améliorations : suggérez des moyens pour renforcer ou ajouter des barrières.
- Documenter l’analyse : rédigez un résumé clair des résultats et des actions recommandées.
- Suivre les actions correctives : vérifiez que les améliorations sont mises en place et qu’elles sont efficaces.
https://www.vectorsolutions.com/courses/safety-management-barrier-analysis/
Risk Tree (Arbre de risques)
Le Risk Tree ressemble à l’FTA mais applique une logique orientée risque plutôt que défaillance pure.
Il est utilisé pour cartographier la combinaison d’événements menant à un risque inacceptable.
Dans un SGSI, il éclaire l’interaction entre menaces, vulnérabilités et impacts, contribuant à prioriser les actions correctives.
Sa complexité croît rapidement avec le nombre de facteurs de risque et peut dépasser les capacités d’analyse de petites équipes.
Comment faire l’arbre des risques
- Définir clairement le risque ou l’événement que vous souhaitez analyser.
- Identifier toutes les causes possibles qui peuvent mener à ce risque.
- Décomposer chaque cause en sous-causes pour mieux comprendre les origines du risque.
- Identifier les conséquences possibles si le risque se produit.
- Rechercher les contrôles ou barrières déjà en place pour réduire ou maîtriser le risque.
- Représenter le tout sous forme d’arbre, en reliant causes, sous-causes, conséquences et contrôles.
- Analyser l’arbre pour repérer les zones critiques et décider des actions préventives ou correctives.
Parent Analysis
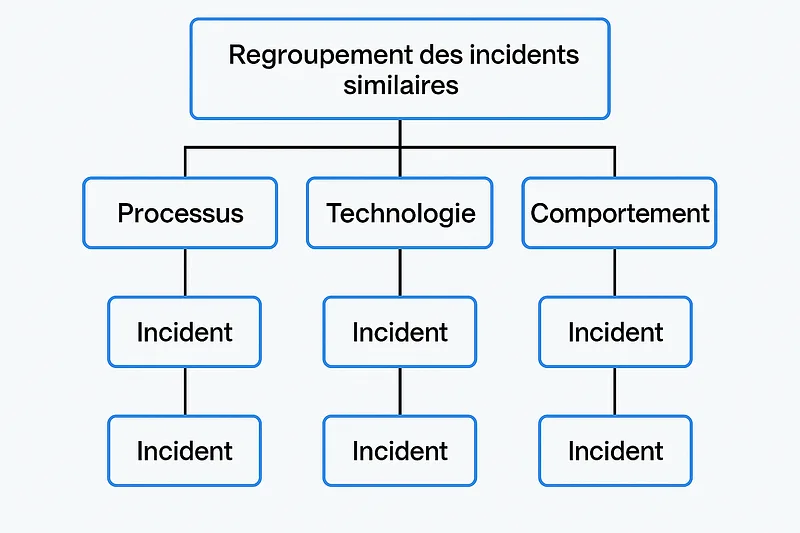
La Parent Analysis regroupe les incidents selon des catégories parentes communes (processus, technologie, comportement) afin d’identifier des tendances structurelles.
Elle s’emploie lorsque plusieurs incidents similaires surviennent au fil du temps.
Ses forces résident dans la vision macro qu’elle offre aux CISO, utile pour orienter des plans d’amélioration continus, mais sa faiblesse est qu’elle fournit une vue brève et peux caché des items spécificités d’un incident particulier.
Comment faire une “Parent analysis”
- Collecte des incidentsRassembler tous les incidents de sécurité sur une période donnée, en veillant à inclure suffisamment de données pour détecter des motifs récurrents.
- Catégorisation des incidentsClasser chaque incident dans une catégorie parente selon un critère commun : Processus (ex. : défaillance dans une procédure) Technologie (ex. : vulnérabilité dans un système ou un logiciel) Comportement (ex. : erreur humaine, phishing réussi)Cette étape est cruciale pour structurer l’analyse et identifier les causes profondes.
- Regroupement des incidents similairesRegrouper les incidents qui partagent la même catégorie parente afin de mettre en lumière des tendances ou des points faibles récurrents.
- Analyse des tendances structurellesExaminer les groupes d’incidents pour comprendre les causes sous-jacentes communes, telles que des failles dans un processus, des lacunes technologiques ou des comportements à risque.
- Synthèse macro pour les décideursPrésenter une vision globale des tendances, ce qui permet d’orienter les plans d’amélioration continue et les stratégies de mitigation.
ChatGPT
Failure Mode and Effects Analysis (Analyse des modes de défaillance et de leurs effets, AMDE)
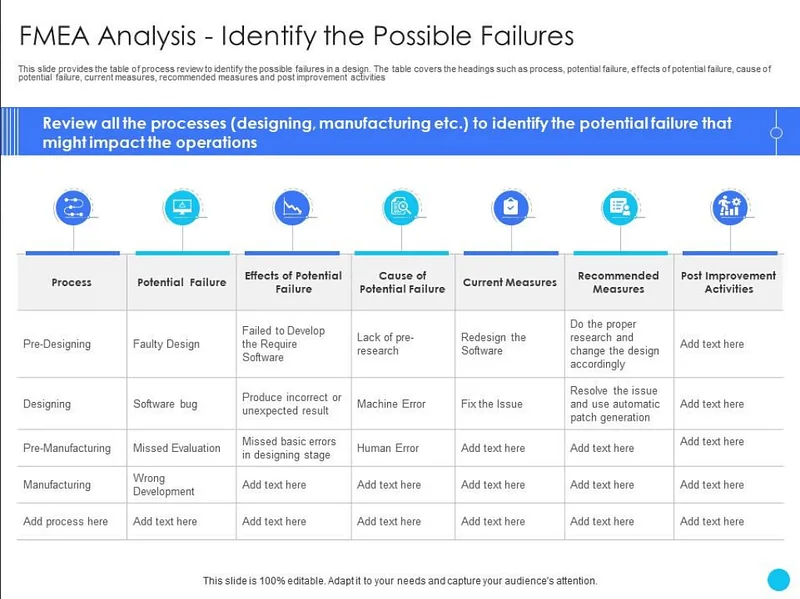
L’AMDE répertorie chaque composant d’un processus ou d’un actif, décrit ses modes de défaillance possibles et en évalue l’effet, la gravité, la probabilité et la détectabilité.
Elle convient aux environnements où la sécurité dépend d’équipements critiques ou de processus répétitifs.
Source: https://en.wikipedia.org/wiki/Failure_mode_and_effects_analysis
Comment faire l’analyse des mode de défaillances
- Identifier le processus, le produit ou le système que vous souhaitez analyser.
- Lister les étapes du processus ou les composants du produit.
- Déterminer les modes de défaillance possibles (comment cela peut échouer).
- Identifier les effets de chaque défaillance (ce qui peut arriver si cela échoue).
- Évaluer la gravité de chaque effet (de faible à critique).
- Identifier les causes possibles de chaque défaillance.
- Évaluer la probabilité d’occurrence de chaque cause.
- Vérifier si des contrôles ou des détections existent déjà, et évaluer leur efficacité.
- Calculer le « score de priorité de risque » (RPN) en multipliant gravité × occurrence × détection.
- Prioriser les actions correctives à mettre en place selon les scores les plus élevés.
- Documenter l’analyse et suivre les améliorations mises en œuvre.
https://www.slideteam.net/blog/top-fmea-templates
Management Oversight and Risk Tree (MORT)
Le MORT est une méthode d’analyse de causes profondes développée pour enquêter sur des événements majeurs, comme des accidents industriels, des défaillances opérationnelles ou des incidents de sécurité. Il est différent des autres:
- Il ne se contente pas d’analyser les défaillances techniques ou humaines.
- Il explore les failles dans le management, la supervision, la prise de décision et les systèmes organisationnels qui ont permis l’incident.
Il cherche à répondre à ces deux questions:
- Qu’est-ce qui a mal fonctionné au niveau technique et opérationnel ?
- Qu’est-ce qui a permis que ces défaillances ne soient ni prévues, ni détectées, ni corrigées ?
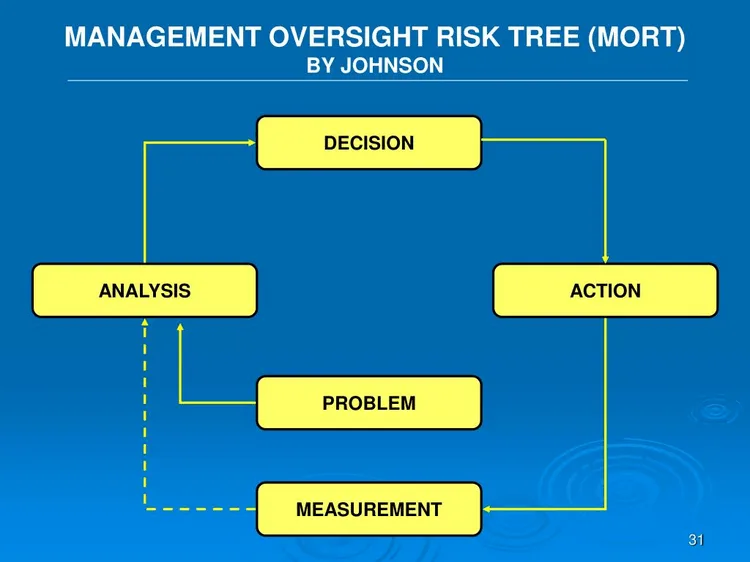
l’approche MORT repose sur deux piliers :
- Un arbre logique et structuré reliant tous les niveaux de causes.
- Un modèle d’évaluation de la direction qui identifie les problèmes systémiques et non seulement les symptômes visibles.
Comment faire une analyse MORT simplement
- Définir l’événement ou l’incident à analyserSoyez précis : nature, date, lieu, impact.
2. Collecter les donnéesRassemblez les rapports, interviews, enregistrements, procédures, logs… et créez une image complète.
**3. Construire l’arbre MORT — **Placez l’incident principal en haut, Branchez les causes immédiates (ex. : panne, erreur humaine, défaut matériel) et Développez vers le bas les causes profondes (ex. : absence de formation, contrôle qualité défaillant, décisions managériales, mauvaise communication).
4. Explorer deux grands axesÉchecs des contrôles: Pourquoi les dispositifs prévus n’ont pas fonctionné.Faiblesses de gestion: Pourquoi l’organisation a échoué à prévenir ou corriger ces problèmes.
5. Utiliser les codes de priorisation (dans l’approche complète) Comme vu dans le MORT classique, utilisez des codes visuels pour distinguer : Ce qui est maîtrisé — Ce qui est incertain — Ce qui représente une faiblesse critique.
6. Identifier les conditions latentesPriorités contradictoires, Objectifs flous, Manque de leadership, Culture de la performance au détriment de la sécurité.
7. Formuler des recommandations correctives robustes
Pour corriger les défaillances techniques, Renforcer la supervision, les processus, la culture et les politiques et mettre en place des indicateurs pour surveiller les changements.
https://www.slideserve.com/Antony/dasar2-k31
Conclusion
Le choix de la méthode d’analyse de cause racine doit refléter la gravité et la complexité de l’incident, la maturité du SGSI et les ressources disponibles.
Une situation simple devrait utiliser la méthode des cinq pourquoi.
À l’inverse, un incident complexe ou récurrent pourra justifier l’emploi d’approches arborescentes comme l’FTA, la CFTA ou le MORT, afin de dévoiler les interdépendances techniques et organisationnelles.
Quel que soit l’outil retenu, l’intégration de la RCA dans le cycle PDCA renforce l’amélioration continue, assure la pérennité des actions correctives prévues à la clause 10.2 et à la fin consolide la robustesse du SGSI face aux menaces actuelles et futures.